Room Prices Analysis (Part 1): Scraping Websites with Python and Scrapy
In this post we’ll describe how I downloaded 1000 room listings per day from a popular website, and extracted the information I needed (like price, description and title).
This is the first of a series of 3 posts on my project Room Prices in Vancouver, make sure to read it for nice insights about the room situation in Vancouver!
What is scraping?
The amount of data that circulates the web is enormous, and a lot of those data is property of big companies. If you’re like me, you probably don’t own any data and one of the way of pulling it from the web is scraping.
Scraping involves fetching a web page, extracting data, following links contained in the page and repeating the process from the beginning until we’re satisfied.
There’s quite a bit of libraries that allows to do scraping in a lot of languages:
In my case I picked scrapy because of my familiarity with it and because it has a lot of neat features out-of-the-box.
While I’m not going to do a step by step tutorial, which is included in the Scrapy Documentation, I’ll give an overview of the steps involved, highlighting specific points not covered (or buried) in the documentation.
Project Structure
First of all, we need to initialize a scrapy project, that is basically a collection of components that make up the whole scraping. To create a project template you do:
scrapy startproject room_listings Scrapy will create a project skeleton, which consist in configuration files plus a set of components needed to be implemented.
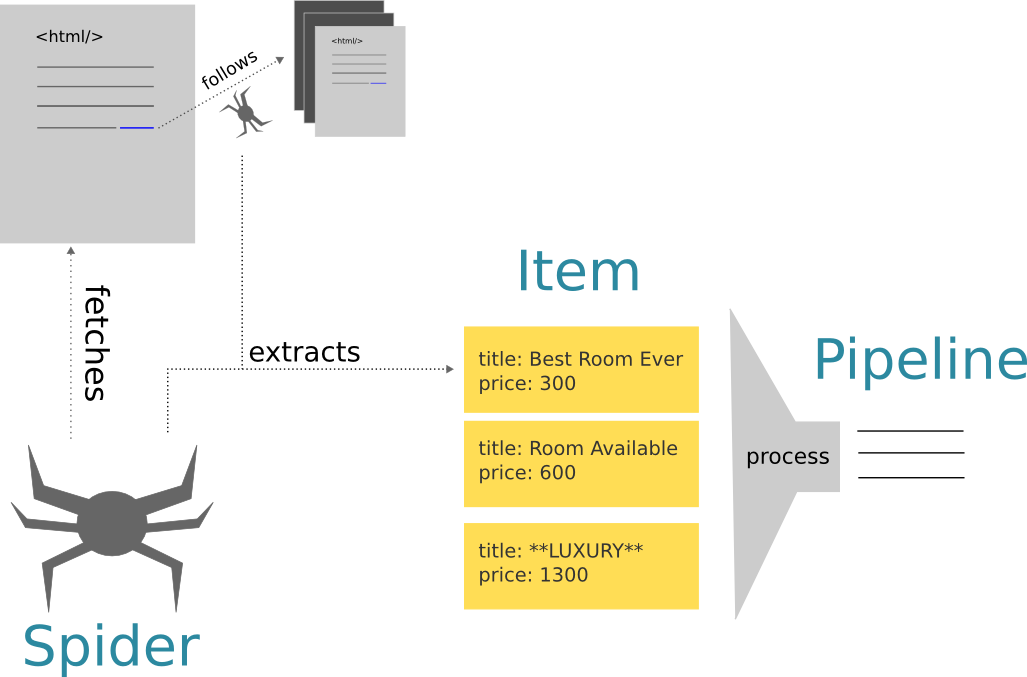
- Spider A class responsible to fetch pages from the web (represented by Response objects), extract the information and output an
Iteminstance, that is the juiced information from the page and recursively follow links. - Items Simple data containers.
- Pipelines Additional post-processing steps, if needed.
The following diagram illustrates the relationships in a friendly and colorful way.
Writing the Item
A first step in the crawler development is to define a data structure to contain our data. In this goes in the module room_spiders/items.py. The definition is nothing special, just a class with a set of fields:
import scrapy
class CraigslistItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
price = scrapy.Field()
maplink = scrapy.Field()
latitude = scrapy.Field()
longitude = scrapy.Field()
url = scrapy.Field()
attributes = scrapy.Field()
size = scrapy.Field()
image_links = scrapy.Field()
time = scrapy.Field()
bedrooms = scrapy.Field()Writing the Spider
The core of the scraper is the Spider. To define a Spider in Scrapy we need to create a Python file in the subdirectory room_spiders/spiders/ and code a new class that inherits from scrapy.contrib.spiders.CrawlSpider.
A scraper needs to some configurations such as which pages to fetch and which links to follow. All of this can be specified using the following class attributes:
allowed_domains: a list of domains that we are allowed to scrapestart_urls: The starting point (or points) of our spiders.rules: A list ofRuleinstances that specify which URL to parse, the parsing function to be called for each page, and the following behaviors.
The following snippet illustrates those concepts in an example spider (file room_spiders/spiders/room_spider.py):
from scrapy.contrib.spiders import Rule, CrawlSpider
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
class RoomSpider(CrawlSpider):
name = "rooms"
allowed_domains = [ "vancouver.craigslist.ca" ]
start_urls = [ "http://vancouver.craigslist.ca/search/roo" ]
rules = (Rule(SgmlLinkExtractor(allow=[r'.*?/.+?/roo/\d+\.html']), callback='parse_roo', follow=False),)
def parse_roo(self, response):
# We do the parsing hereWhen we launch the scrapy executable (with the command scrapy crawl), the spider will match the URL specified in the rules and call the appropriate parsing function (in this case parse_roo)
Parsing
The parsing code is implemented in the parse_roo method, that takes a Response object as its only argument.
In the Scrapy framework, HTML elements are fetched from the page using the XPath syntax that lets you easily navigate the HTML tags and attributes.
An example is as follows. The title and content were easily extracted by referring to the appropriate
id attributes in the page. Notice also the longitude and latitude of the posting were extracted from the
a google map link, when present.
def parse_roo(self, response):
url = response.url
titlebar = response.xpath('//*[@id="pagecontainer"]/section/h2/text()').extract()
title = ''.join(titlebar)
price = response.xpath('//*[@class="price"]/text()').extract()
price = int(re.search(r'\$(\d+)', price[0]).group(1))
content = response.xpath('//*[@id="postingbody"]').extract()[0]
maplink = response.xpath('//*[@id="pagecontainer"]/section/section[2]/div[1]/div/p/small/a[1]').extract()
longitude = None
latitude = None
mapdata = response.xpath('//*[@id="map"]')
if len(mapdata) != 0:
longitude = float(mapdata.xpath("@data-longitude").extract()[0])
latitude = float(mapdata.xpath("@data-latitude").extract()[0])
attributes = response.xpath('//*[@id="pagecontainer"]/section/section[2]/div[1]/p').extract()[0]
image_links = response.xpath('//*[@id="thumbs"]/a/@href').extract()
time = response.xpath('//*[@id="display-date"]/time/@datetime').extract()[0]
item = CraigslistItem(url=url,
size=None,
price=price,
title=title,
content=content,
maplink=maplink,
longitude=longitude,
latitude=latitude,
attributes=attributes,
image_links=image_links,
time=time)
return itemRemember also that at every change of layout the scraper can get completely thrown off, make sure to keep monitor if there’s any error when you run the spider with scrapy crawl.
Parsing 1000 posts at a time.
How do we manage to scrape all the pages we need? One approach is to set the option follow=True in the scraping rules, that instructs the scraper to follow links:
class RoomSpider(CrawlSpider):
## ...
rules = (Rule(SgmlLinkExtractor(allow=[r'.*?/.+?/roo/\d+\.html']), callback='parse_roo', follow=True),)However that simply keeps parsing all the listings available in the website. A better solution is to set follow=False and write multiple start_urls entries, corresponding to the different “paginations” of the listing search page:
start_urls = ["http://vancouver.craigslist.ca/search/roo",
"http://vancouver.craigslist.ca/search/roo/?s=100",
"http://vancouver.craigslist.ca/search/roo/?s=200",
# etc...
]Data Storage using Pipelines
Now that we produced an Item from our page, how do we store it?
One simple way to store is by using the builtin feed exports in Scrapy:
scrapy crawl rooms -o items.jsonHowever I found that appending stuff is much more efficient by using a Pipeline and saving the items to a database (in my case Postgres).
A Pipeline is just a class defined in pipelines.py that takes an Item as an input, and outputs another Item. Of course in between we can have any side effects we want, including additional data storage and logging. In the following snippet we connect to a Postgres database and store the items in a table called raw_data.
class PostgresPipeline(object):
def __init__(self):
import psycopg2
self.conn = psycopg2.connect(user="pi",
dbname="cg_scraping",
host='/var/run/postgresql/')
def process_item(self, item, spider):
cur = self.conn.cursor()
cur.execute('''
insert into raw_data ( title, url, price, bedrooms, maplink,
longitude, latitude, updated_on, content, image_links,
attributes, size, parsed_on )
values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);
''', [
item['title'],
item['url'],
item['price'],
item.get('bedrooms', None),
item['maplink'],
item['longitude'],
item['latitude'],
item['time'],
item['content'],
item['image_links'],
item['attributes'],
item['size'],
datetime.datetime.now()])
self.conn.commit()
return itemScheduling the Spider
I setup a Raspberry Pi 2 to run the spider every day at 23:12 by creating a script with the crawing command, and running it using a simple cron job.
12 23 * * * /path/to/scraping/script
If you want the time to be not exact you can always let your script sleep for some seconds before starting the scraper. In the following code we sleep between 1 and 10 seconds.
sleep $[ ( $RANDOM % 10 ) + 1 ]s
# Rest of the script ...Be (or pretend to be) a Good Spider
Spiders are quite powerful and may submit tons of request in a short period of time. However, this is not a good practice as it burdens the servers, and websites typically adopt countermeasures to prevent excessive load.
Here are a few tips to avoid getting banned:
- limit the requests to a minimum. Like 1 request every 3 seconds ( by setting the attribute
download_delayin your spider) - randomize the time between each request. This is enabled by default by Scrapy.
- change IP between requests. I didn’t use this measure as I didn’t scrape so intensely to constitute an issue, but apparently websites such as crawlera offer this type of service (among other things).
What’s next?
In the next post we’ll see how to clean the raw-data and how to geolocate Vancouver neighbourhoods from latitude and longitude.
Go to Part 2: Data Cleaning and Geolocation with Python and Shapely